Optimal Prescriptive Trees¶
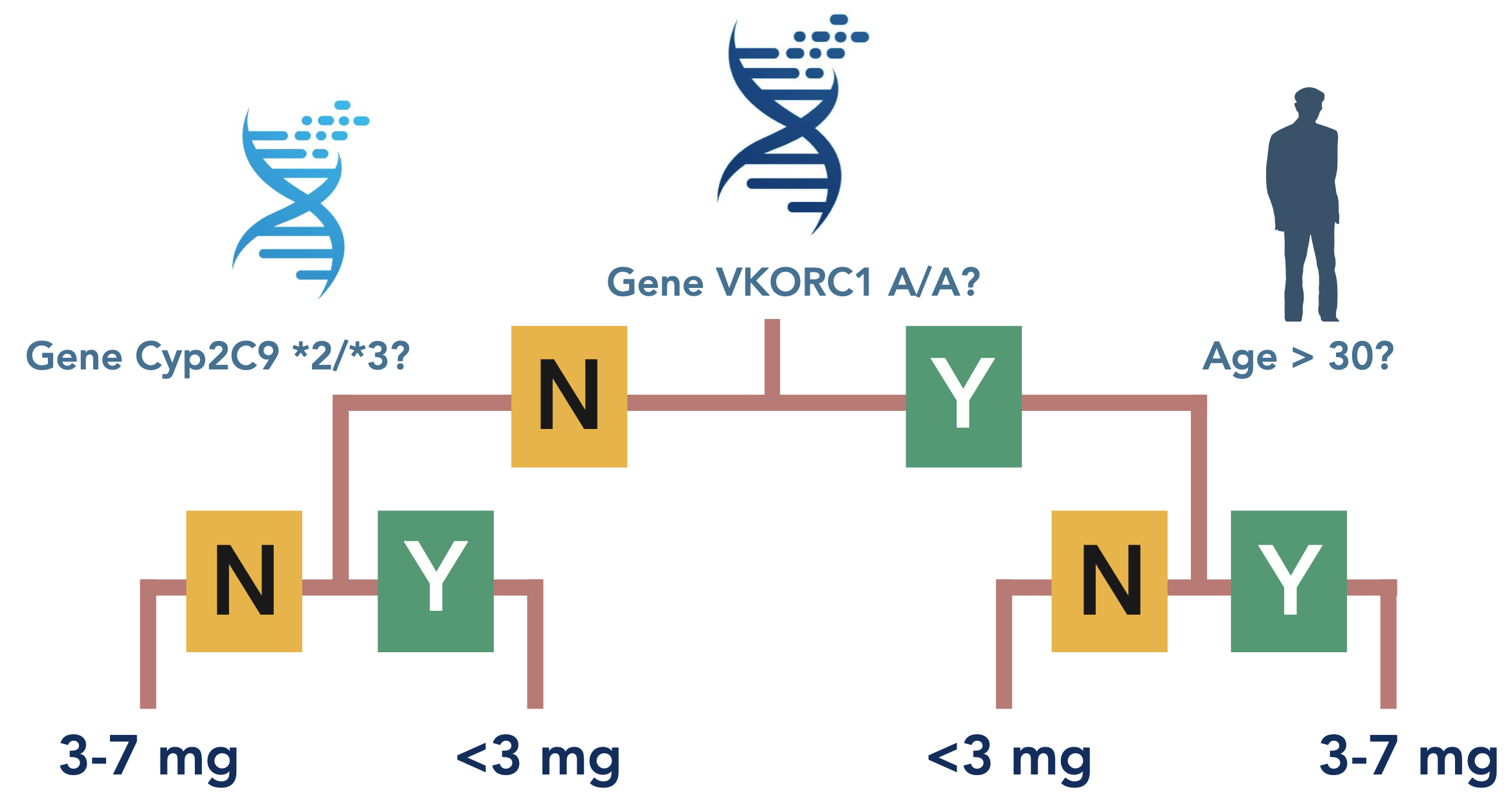
A prescriptive tree is a personalized treatment assignment policy that is learned from either randomized or observational data. The FlowOPT_* classes are mixed-integer optimization (MIO) based implementations for learning optimal prescriptive trees of a given depth. The image below shows an application of this method on learning optimal warfarin dosing for patients; people with certain phenotypes and past a certain age react differently to different doses of the drug. Refer to the corresponding paper for a complete treatment of the prescriptive tree method (Jo et al., 2021).
Objective Function Choices¶
The package offers three different objectives to maximize, each corresponding to a different method of counterfactual policy evaluation as proposed by Dudík et al., 2011.
1. Inverse Propensity Weighting (IPW)¶
IPW relies on reweighting the outcome for each individual in the dataset by the inverse of their propensity score, defined as the probability of assigning a particular treatment to an individual given their covariates. If the historical treatment assignment policy is known, then this method is the most reliable estimator to use. When the true policy is unknown, however, one can also estimate the propensity scores using machine learning.
In order to execute IPW, use class FlowOPT_IPW, which requires an additional parameter ipw in the fit() function corresponding to the propensity weights (NOT the inverse of the weights) of each datapoint.
2. Direct Method (DM)¶
The direct method (DM) relies on predicting counterfactual outcomes using a machine learning method. First, one partitions the dataset by treatment group. For each treatment group, fit a machine learning model on that subpopulation and predict on the entire dataset. The result functions as a prediction of what would happen if everyone in the dataset received that particular treatment.
If the data at hand is close to a randomized trial and has sufficiently many observations, DM is a good estimator to use because its predictions are less likely to be biased.
In order to execute DM, use class FlowOPT_DM, which requires an additional parameter y_hat in the fit() function corresponding to the counterfactual outcome estimations of each datapoint.
3. Doubly Robust Method (DR)¶
Doubly robust (DR) estimation is a family of techniques that combine two estimators. The package applies a doubly robust estimator by combining the IPW and DM methods. In doing so, it dampens the errors brought about by DM’s counterfactual predictions; DR also typically has lower variance than IPW.
If one is unsure which method to employ, DR is often the safest choice since it takes advantage of both IPW and DM estimators.
In order to execute DR, use class FlowOPT_DR which requires both y_hat and ipw in the fit() function.
Handling Integer Features¶
In addition to binary input features, FlowOPT_* can be applied to datasets with categorical and integer features by first preprocessing the data. For each categorical feature, one needs to encode it as a one-hot vector, i.e., for each level of the feature, one needs to create a new binary column with a value of one if and only if the original column has the corresponding level. A similar approach for encoding integer features can be used with a slight change. The new binary column should have a value of one if and only if the main column has the corresponding value or any value smaller than it. ODTlearn provides a function called binarize for taking care of the binarization step where given a dataframe with only categorical/integer columns it outputs a binarized dataframe.
References¶
Dudík, Miroslav, John Langford, and Lihong Li. “Doubly robust policy evaluation and learning.” Proceedings of the 28th International Conference on Machine Learning, ICML 2011.
Jo, N., Aghaei, S., Gómez, A., & Vayanos, P. (2022). Learning optimal prescriptive trees from observational data. arXiv preprint arXiv:2108.13628. https://arxiv.org/pdf/2108.13628.pdf